如何在cuda C/C++中重叠数据传输
CUDA流(stream)
在CUDA中流是在device中执行的操作序列他们由host 代码因其。当在流中的操作被安排在以指定的孙旭执行的时候,在不同的流中的操作可能被交叠,当可能的时候,他们可以并行运行。
默认的流
在CUDA中所有的device操作(内核函数和数据传输)都在流中运行。当没有流指定的时候,默认的流(null stream)被使用。默认的流不同于其他的流因为他有一个同步流对应在device中的操作:没有操作在默认的六种将知道所有之前在device中产生的产生的操作完成后开始,一个在默认流中的操作必须在任意其他操作开始前完成。
请注意在2015年释放的CUDA 7,引进了一个新的选项用于在每个host线程分割默认的流,对待per-thread默认流作为正常的流(他们不在其他的流中同步操作),读更多的信息查看(这里)
让我们查看一些使用默认流的简单代码,讨论如何操作来自host层面的的进程和在device上操作一样。
cudaMemcpy(d_a,a,numBytes,cudaMemcpyHostToDevice);
increment<<<1,N>>>(d_a)
cudaMemcpy(a,d_a,numBytes,cudaMemcpyDeviceToHost);
在上面的代码中,来自device,所有的三个操作被默认的流引起他们将按照引起的孙旭执行。
对于Host层面,明确的数据阐述被阻塞或者同步传输,尽管内核启动是异步的。因此host-to-device 数据传输在第一行是同步的,CPU线程将知道host-to-device传输完成后才到达内核。当内核产生后,CPU线程移动到第三行,但是在这行因为device-side执行顺序不能开始。
内核函数启动的异步行为使得host的perspective使得重叠device和host计算非常简单。我们可以修改代码添加CPU计算实现。
cudaMemcpy(d_a,a,numBytes,cudaMemcpyHostToDevice);
increment<<<1,N>>>(d_a)
myCpuFunction(b)
cudaMemcpy(a,d_a,numBytes,cudaMemcpyDeviceToHost)
在上面的代码中,只要increment()内核在device上启动,CPU执行myCpuFunction(),重复的在CPU上执行结合在GPU上的内核执行。是否host函数或者device内核先完成不影响子序列device-to-host传输,仅仅在内核完成后。从device的视角,和之前的例子没有任何改变;device完全不用考虑myCpuFunction()
Non-default streams
非默认的流在CUDA C/C__中被声明,创建在host中被销毁,如下:
cudaStream_t stream1;
cudaError_t result;
result = cudaStreamCreate(&stream1)
result = cudaStreamDestroy(stream1)
为了生成一个数据传输到non-default stream我们使用cudaMemcpyAsync(),它和cudaMemcpy()类似,但是接受一个流标志作为第五个参数
result = cudaMemcpyAsync(d_a,a,N,cudaMemcpyHostToDevice,stream1)
cudaMemcpyAsync()不在host中阻塞,因此在纯属被引起后控制返回到host线程。有这个例程的cudaMemcpy2DAsync()和cudaMemcpy3DAsync()可以在指定的流中异步传输2D和3D数组。
为了产生一个内核到non-default流我们指定流标识符作为一个执行配置参数(第三个执行配置参数分配共享的device memory,之后我们会谈到,现在使用0)
increment<<<1,N,0,stream1>>>(d_a)
和流同步
因为所有的在non-default stream中的操作现在non-blocking对应host代码,你讲润兴situation这里你需要同步host代码和流中的操作。有一些方法做到这些。"heavy hammer"方法用在cudaDeviceSynchronize(),它阻塞主代码知道之前在device中产生的操作完成。在多数情况下是过度杀伤,实际上可能伤害性能导致停止整个device和host线程。
CUDA stream API有多个没那么严苛的同步host和流的方法。函数cudaStreamSynchronize可以使用组摄线程知道之前所有在流中产生的操作完成。 函数cudaStreamQuery测试是否所有指定流产生的的操作是否完成,没有阻塞主线程。函数cudaEventSynchronize(event)和cudaEventQuery(event)类似他们的流伙伴,除了他的结果基于是够指定时间呗记录而不是时间被记录在不同的流中或者在不同的设备中。
重叠内核执行和数据传输
之前我们展示了如何在host执行代码覆盖流中的内核执行。但是我们的主要目的是展示如何重叠内核操作和数据传输。有一些要求:
- 设备必须有并行复制和执行的能力。它可以被cudaDeviceProp结构的deviceOverlap执行。或者来自deviceQuery样本包含在CUDA SDK/Toolkit包含。几乎所有的计算能力在1.1以上的device都有这个能力
- 内核执行和数据传输必须包含在不同的,non-defaul的流中。
- 主memory调用数组传输的时候必须pinnedmemory
让我们修改我们的代码使用多个流查看是否我们能获得任何重叠。完整的代码在这里。在修改的代码中,我们拆开大小为N的数组为streamSize元素。因此内核操作独立于所有的元素,每个chunk可以单独处理。non-defaul的流数用nStreams=N/streamSize。有多种方法实现数据的结构和处理;一种是下面代码中的为每个数组的chunk训练所有的操作
另一个批方法类似,产生所有的host-to-device传输,接着所有的内核启动然后所有的device-to-host传输,如下面的代码 ``` for (int i = 0; i < nStreams; ++i) { int offset = i * streamSize; cudaMemcpyAsync(&d_a[offset], &a[offset],for (int i = 0; i < nStreams; ++i) { int offset = i * streamSize; cudaMemcpyAsync(&d_a[offset], &a[offset], streamBytes, cudaMemcpyHostToDevice, stream[i]); kernel<<<streamSize/blockSize, blockSize, 0, stream[i]>>>(d_a, offset); cudaMemcpyAsync(&a[offset], &d_a[offset], streamBytes, cudaMemcpyDeviceToHost, stream[i]); }>)
}streamBytes, cudaMemcpyHostToDevice, cudaMemcpyHostToDevice, stream[i]);
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
kernel<<
for (int i = 0; i < nStreams; ++i) { int offset = i * streamSize; cudaMemcpyAsync(&a[offset], &d_a[offset], streamBytes, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToHost, stream[i]); }>)>)>)
异步方法显示生成正确的结果,在两种情况下操作被同一个流需要被执行的顺序产生。然是两个方法非常不同在指定GPU使用上。在Tesla C1060{计算能力1.3}下面的代码给出的结果如下:
Device : Tesla C1060
Time for sequential transfer and execute (ms ): 12.92381 max error : 2.3841858E -07 Time for asynchronous V1 transfer and execute (ms ): 13.63690 max error : 2.3841858E -07 Time for asynchronous V2 transfer and execute (ms ): 8.84588 max error : 2.3841858E -07
在Tesla C2050(计算能力为2.0)我们将得到下面的结果
Device : Tesla C2050
Time for sequential transfer and execute (ms ): 9.984512 max error : 1.1920929e -07 Time for asynchronous V1 transfer and execute (ms ): 5.735584 max error : 1.1920929e -07 Time for asynchronous V2 transfer and execute (ms ): 7.597984 max error : 1.1920929e -07
这里我们首先使用blocking传输报告序列传输和内核执行,我们使用一步加速。为什么两个移步方法指定在不同的架构上不同?为了解释这个结果我们需要了解一点CUDA devices调用和执行任务的。CUDA device包含用于多任务的引擎,按照产生的顺序排队。在不同引擎中的任务相互独立操作,但是在人易引起所有外部依赖丢失后;在每个引擎中的任务的队列按照产生的顺序执行。C1060有一个复制引擎和单个内核引擎。在是建行上执行我们的示例代码显示如下:

为了简单我们假设host-to-device阐述,kernel执行,device-to-host传输时间几乎相等(内核代码被选中为了获得这点)。正如之前的序列内核,没有重叠在任何操作。对于第一个一步版本我们的带买吗执行在复制引擎上是:H2D stream[1],D2H stream[2],D2H stream[2]这样。这也是为什么我们步执行数据传输的原因。对于斑斑2,然而所有的host-to-device传输被产生在所有的device-to-host传输之前,重叠以很低的执行时间运行。重我们的见图,我们希望执行一步版本2到8/12序列版本,或者8.7ms确定之前给定的实践结果。
在C2050上,两个特征交互交织和C1060不同。C2050有两个复制引擎,host-to-device传输和另一个device-to-host传输,正如单个内核引擎。下面的图阐述了我们在C2050上执行
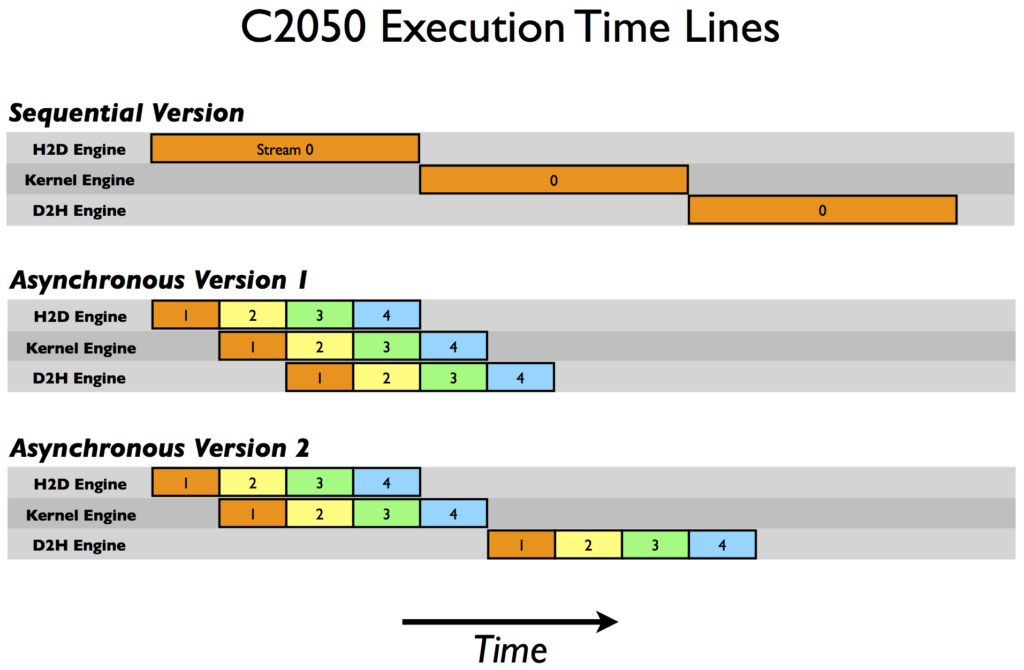
有两个复制引擎解释为什么一步版本1在C2050上获得更好的速度:device-to-host传输数据在流stream[1]中不阻塞host-to-device传输数据在stream[i+1]正如它在C1060中因为在C2050有一个分开的引擎处理复制。图预示了执行时间相比序列版本被砍了一半。这是显示时间结果的概括。
但是关于在C2050版本2的性能衰减是什么?这和C2050的并行运行多个内核的能力有关。当多内核被产生back-to-back在不同的流(non-default)中,调度器尝试并行执行这些内核正如结果延迟一个引号正常在每个内核计算完成后产生(表示kick off device-to-host传输)知道所有的重复在内核执行同时device-to-host传输。见图预测了异步版本2对于序列版本9/12的时间,或者7.5ms,这通过我们的时间结果确定。
一个更多细节例子的细节描述在[CUDA Fortran Asyncronous Data Transfer](http://www.pgroup.com/lit/articles/insider/v3n1a4.htm)。好消息是对于device计算能力的3.5(k20系列)Hyper-Q特性小数了tailor启动顺序的需要,因此上面的方法将有效/我们将在后续讨论使用Kpler特性的,但是现在代码运行的结果在Tesla K20c GPU上。正如你看到的,两个与不方法获取了和同步代码同样的加速
Device : Tesla K20c Time for sequential transfer and execute (ms): 7.101760 max error : 1.1920929e -07 Time for asynchronous V1 transfer and execute (ms): 3.974144 max error : 1.1920929e -07 Time for asynchronous V2 transfer and execute (ms): 3.967616 max error : 1.1920929e -07 ```