caffe训练lenet
- 下载mnist数据集
- 生成lmdb数据库文件
- 编写lenet
训练
下载mnist文件
- 生成lmdb脚本
create_mnist.sh如下:
#!/usr/bin/env sh
# This script converts the mnist data into lmdb/leveldb format,
# depending on the value assigned to $BACKEND.
# 这句语句告诉bash如果任何语句的执行结果不是true则应该退出
set -e
# lmdb文件保存路径
EXAMPLE=examples/mnist
# mnist数据集所在位置
DATA=data/mnist
# 创建数据集的二进制文件的位置
BUILD=build/examples/mnist
# 生成数据库后端
BACKEND="lmdb"
# 启动后端说明
echo "Creating ${BACKEND}..."
# 如果EXAMPLE已经存在lmdb文件则将其删除
rm -rf $EXAMPLE/mnist_train_${BACKEND}
rm -rf $EXAMPLE/mnist_test_${BACKEND}
# 调用构建mnist文件的二进制文件生成lmdb数据库格式的文件
$BUILD/convert_mnist_data.bin $DATA/train-images-idx3-ubyte \
$DATA/train-labels-idx1-ubyte $EXAMPLE/mnist_train_${BACKEND} --backend=${BACKEND}
$BUILD/convert_mnist_data.bin $DATA/t10k-images-idx3-ubyte \
$DATA/t10k-labels-idx1-ubyte $EXAMPLE/mnist_test_${BACKEND} --backend=${BACKEND}
echo "Done."
lenet网络架构如下:
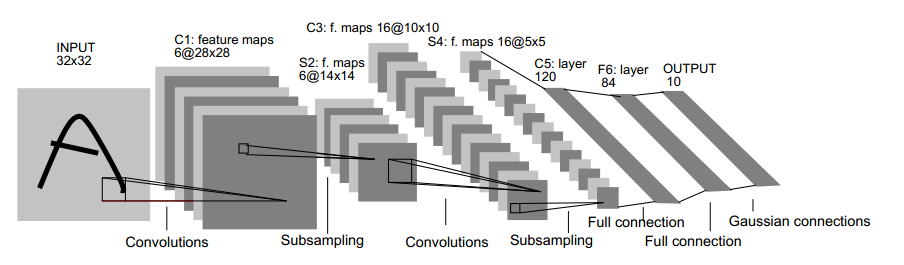 )
)
- 构建
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb"
batch_size: 100
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
每一个layer有如下参数:
- name:层的名字
- type:输入数据通常为给定的lmdb
- transform_param:变换图像像素到0-1,每个像素乘上$$\frac{1}{255}=0.00390625$$
- param{lr_mult:1}:层的可学习参数,这里表示权重学习率和求解器学习率一致,param{lr_mult:1}偏执学习率为为2更容易收敛
- convolution_param:
- num_output:输出通道为20
- kernel_size:卷积核尺寸为5
- stride:卷积核移动步长
- weight_filler { type: "xavier" } 表示自动决定输入输出神经元的初始缩放
- bias_filler { type: "constant" } 偏执初始化为常数,默认为0
- pooling_param:池化层参数
- kernel_size:2:表示池化层4个元素融合
- stride:2池化移动的尺寸为2
- pool:max池化方式为max池化
- data_param:
- source:lmdb数据库文件的名字
- backend:数据库后端
- batch_size:每批次的数据个数
- top:为层端输入或者输出
- bottom:"conv1":表示这层输入为conv1
- include {
phase: TRAIN
}:表示训练的时候包含网络定义
定义求解器:
```
The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"test_iter specifies how many forward passes the test should carry out.
In the case of MNIST, we have test batch size 100 and 100 test iterations,
covering the full 10,000 testing images.
test_iter: 100Carry out testing every 500 training iterations.
test_interval: 500The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01 momentum: 0.9 weight_decay: 0.0005The learning rate policy
lr_policy: "inv" gamma: 0.0001 power: 0.75Display every 100 iterations
display: 100The maximum number of iterations
max_iter: 10000snapshot intermediate results
snapshot: 5000 snapshot_prefix: "examples/mnist/lenet"solver mode: CPU or GPU
solver_mode: GPU
- net:定义的网络的prototxt文件目录
- test_iter:前向传递次数,在这个mnist例子中,测试批大小为100,测试迭代100
- test_interval:每500训练列带后测试
- base_lr:基本的学习率,momentum和网络的权重偏移
- lr_policy:学习率策略
- gamma:求解器参数
- power:0.75
- display:100
- snapshot:间隔结果
- snapshot_prefix:
- solver_model:求解器计算模式
训练脚本
```#!/usr/bin/env sh
set -e
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt $@
` ``
结果如下:
I0409 17:10:25.965229 3759 solver.cpp:418] Test net output #1: loss = 0.0287437 (* 1 = 0.0287437 loss) I0409 17:10:25.965239 3759 solver.cpp:336] Optimization Done. I0409 17:10:25.965245 3759 caffe.cpp:250] Optimization Done.
```