OpenCV使用caffe预先训练的网络识别
更过细节查看这里
 在通常的深度学习中,输入到训练好的框架中的图像需要先减去均值。例如ImageNet训练集是
在通常的深度学习中,输入到训练好的框架中的图像需要先减去均值。例如ImageNet训练集是R=103.93,G=116.77,B=123.68,有限情况下是按通道计算结果是生成$$M\times N$$矩阵。在这种情况下在训练/测试阶段$$M\times N$$矩阵对于每个通道从输入图像中减去。,当我们准备好传入图像到我们的网络中的时候(无论是测试或者训练),我们减去均值,$$\mu$$对于输入图像的每个输入通道:
$$ R = R-\mu_R\ G = G-\mu_G\ B = B-\mu_B
$$ 你也可以有一个缩放因子$$\delta$$
$$ R = (R-\mu_R)/\sigma\ G = (G-\mu_G)/\sigma\ B = (B-\mu_B)/\sigma
$$
$$\sigma$$是训练集的标准差,主要用来将输入空间缩放到指定范围,这个操作依赖于指定的架构。
下面是减去均值后图像的对比效果图:

函数cv2.dnn.blobFromImage:创建4维blob,从中心resize和crop图像(可选),同样深度(通道数目),用同样的处理。
cv2.dnn.blobFromImage和cv2.dnn.blobFromImages函数几乎一致。函数用法如下:
blob = cv2.dnn.blobFromImage(image,scalefactor = 1.0,size,mean,swapRB=True)
- image:这是我们想要传入深度神经网络训练的图像
- scalefactor:在执行完成减去均值后我们可以选择缩放我们的图像。值定义为1.0表示不缩放,我们可以设置为其它值,但是注意的是scalefactor应该是$$\frac{1}{\sigma}$$,实际上我们用scalefactor乘上输入通道。
- size:这里应用CNN希望的大小,顶级网络大小通常是$$224\times 224,227\times 227,299\times 299$$
- mean 这里是我们减去的均值,可以使一个三元组表示RGB或者可以使单个值表示每个通道都减去这个值。如果你执行均值减,确保使用3元祖(R,G,B)顺序,特别是当你使用默认的行为
swapRB=True的时候 swapWB:OpenCV假设图像是BGR通道顺序,然而均值假设使用RGB顺序。为了解决冲突我们可以通过设置这个值为True交换RB的顺序/默认OpenCV为我们执行了这个转换。cv2.dnn.blobFromImage函数返回一个执行了均值减去,正规化和通道交换的blob。
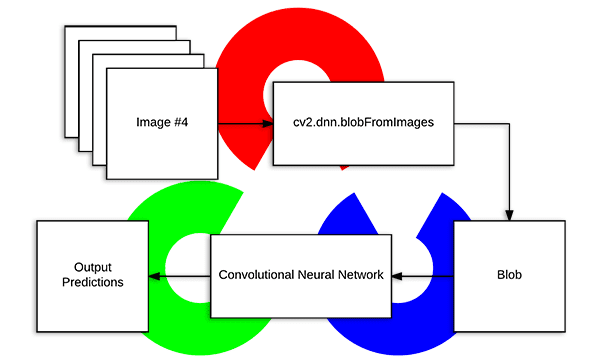
cv2.dnn.blobFromImages(image,scalefactor=1.0,size,mean,swapRB=True)函数接受多张图片是我们能批量的处理图像数据。如果你正在处理多张或者多帧图像,这个函数开销更小更快的处理图像/帧。
使用摄像头实时识别的这里
from imutils import paths
import numpy as np
import cv2
# 读取文件输出类别列表
rows = open('synset_words.txt').read().strip().split('\n')
classes = [r[r.find(" ")+1:].split(",")[0] for r in rows]
# 读取训练好的caffe网络
net = cv2.dnn.readNetFromCaffe('bvlc_googlenet.prototxt','bvlc_googlenet.caffemodel')
# 开启摄像头
cap = cv2.VideoCapture(0)
while True:
# 读取摄像头捕获的视频流
ret,frame = cap.read()
if ret:
# 按照GoogleNet要求将图像resize为224x224
image = cv2.resize(frame.copy(),(224,224))
# 预处理图像,包括减去均值,resize等
blob = cv2.dnn.blobFromImage(image,1,(224,224),(104,117,123))
# 输入网络
net.setInput(blob)
# 预测输出列表
preds = net.forward()
# 将输出列表概率按照从小到大排列然后反向切片获取概率最大的label的索引
idx = np.argsort(preds[0])[::-1][0]
# 输出索引和概率信息
text = "Label:{},{:.2f}%".format(classes[idx],preds[0][idx]*100)
cv2.putText(frame,text,(5,25),cv2.FONT_HERSHEY_COMPLEX_SMALL,0.7,(0,0,255),2)
cv2.imshow('image',frame)
k = cv2.waitKey(1)
if k == 27:
break
else:
continue
cap.release()
cv2.destroyAllWindows()